
🙋♂️ 个人简介
李政霖,博士,副教授,博士生导师。本硕毕业于大连理工大学,博士毕业于英国谢菲尔德大学。上海市海外高层次人才,主持国家自然科学基金青年、启明星培育等多项纵向课题、以第一及通讯作者在重要学术期刊和国际会议上发表多篇论文,其中包括 IEEE Trans. on Industrial Informatics,IEEE Trans. on Intelligent Transportation Systems,IJCAI等。中国人工智能学会智能机器人专委会委员、Cyborg and Bionic Systems期刊(IF 10.5)青年编委。
📝 主要研究领域
1. 自动驾驶/机器人感知及端到端系统:包括多传感器融合感知、协同感知、端到端自动驾驶、占用网格估计、水面无人艇感知等;
多视图融合感知
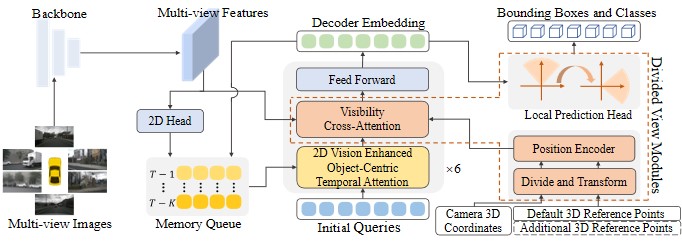

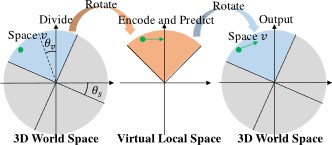
将全局空间进行多层级分割,与虚拟视角空间对齐并进行位置编码,以低计算量实现全局注意力
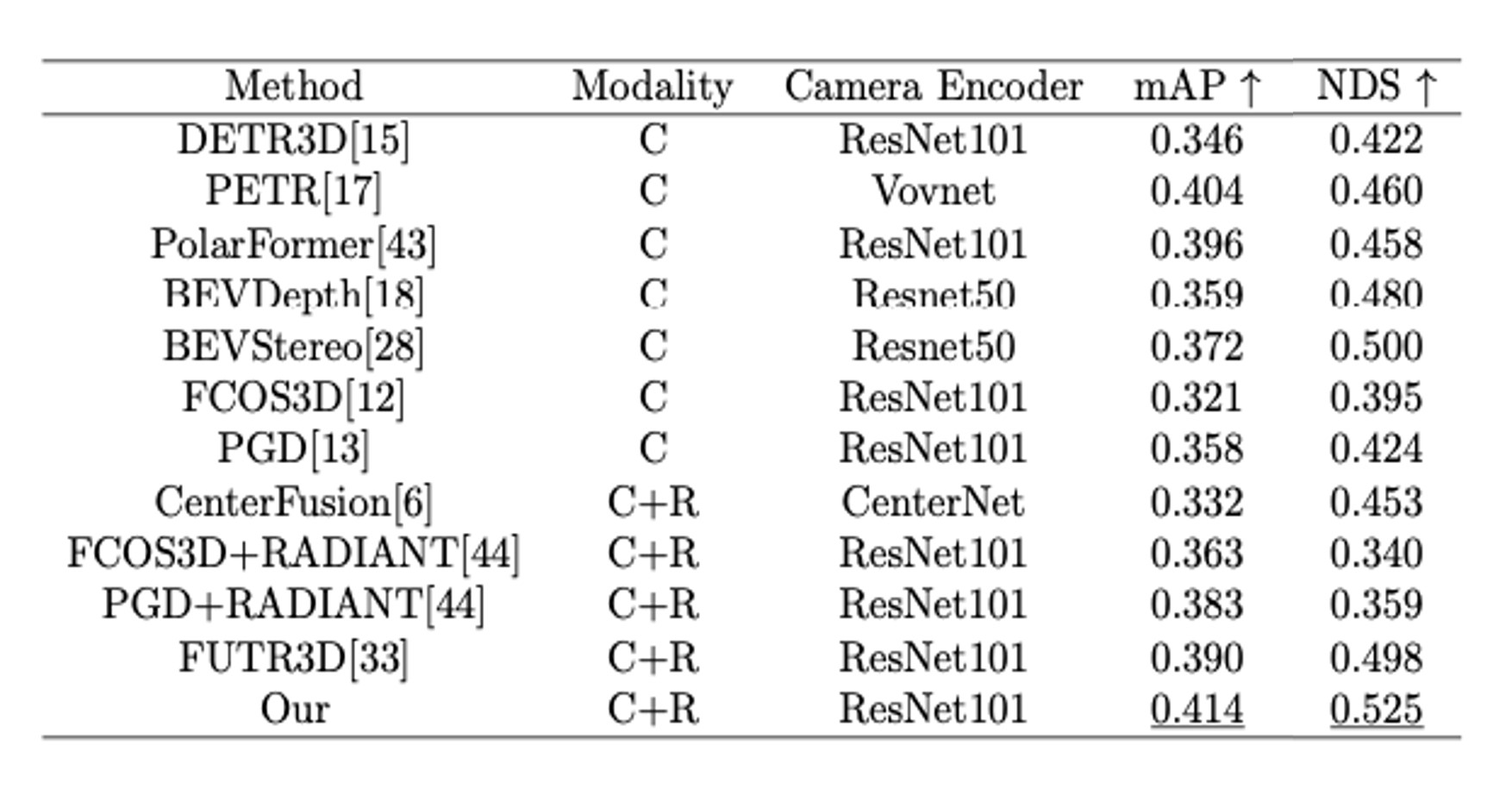
DVPE: divided view position embedding for multi-view 3D object detection,IJCAI 2024(CCF A)
视觉-毫米波雷达水面融合感知
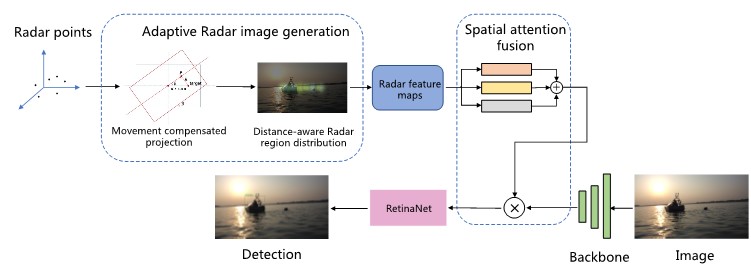
Target Detection for USVs by Radar-vision Fusion with Swag-robust Distance-aware Probabilistic Multi-modal Data Association,IEEE Sensors Journal,2024
- 减弱水面反射、平台晃动、逆光或阴雨的影响
- 在复杂场景下具有可靠检测性能

视觉-毫米波雷达融合感知
视觉-毫米波雷达动态交互3D目标检测
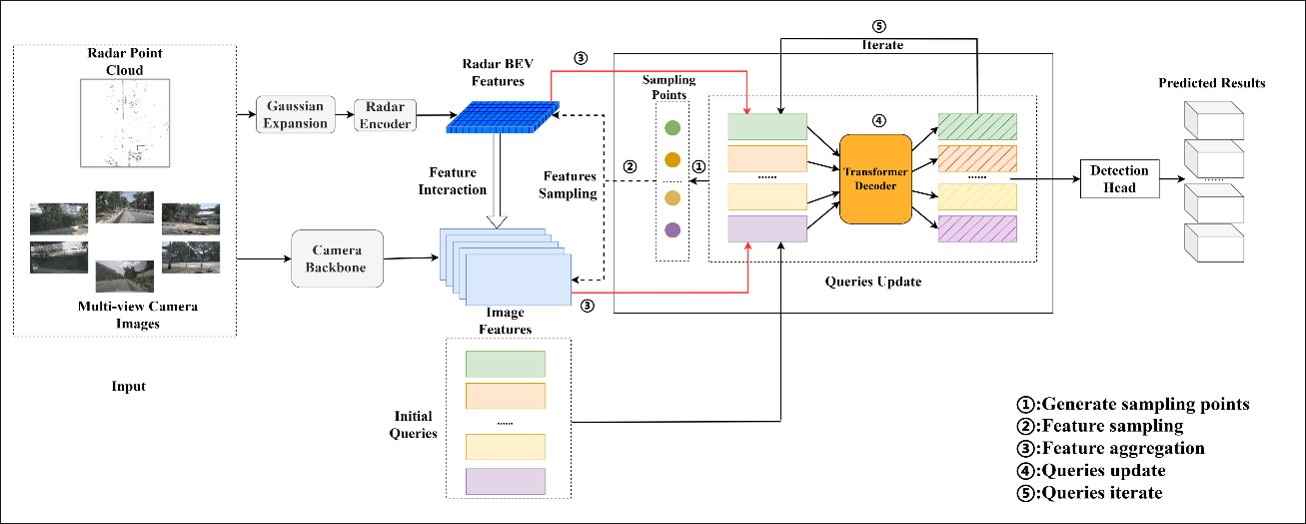
视觉光流与毫米波雷达融合的关键目标速度解构
端到端系统
端到端自动驾驶系统可定义为完全可微的过程,以原始传感器数据为输入,并产生规划和/或低级控制动作作为输出。
- 大模型赋能垂直领域任务
- 端到端信息交互优化集群协同
- 减少累积误差,实现精确控制
- 感知-规划端到端系统不确定性
2. 机器人训练数据生成与增强:包括新视角图像合成、多模态数据生成、数据增强、风格迁移等;
新视角合成 (Novel View Synthesis) :给定源图像 (Source Image) 及源姿态 (Source Pose),以及目标姿态 (Target Pose),渲染生成目标姿态对应的的图片 (Target Image)。

3. 机器学习与计算机视觉:包括信息融合、深度学习的不确定性量化与分析、大模型微调、增量学习/终身学习等。
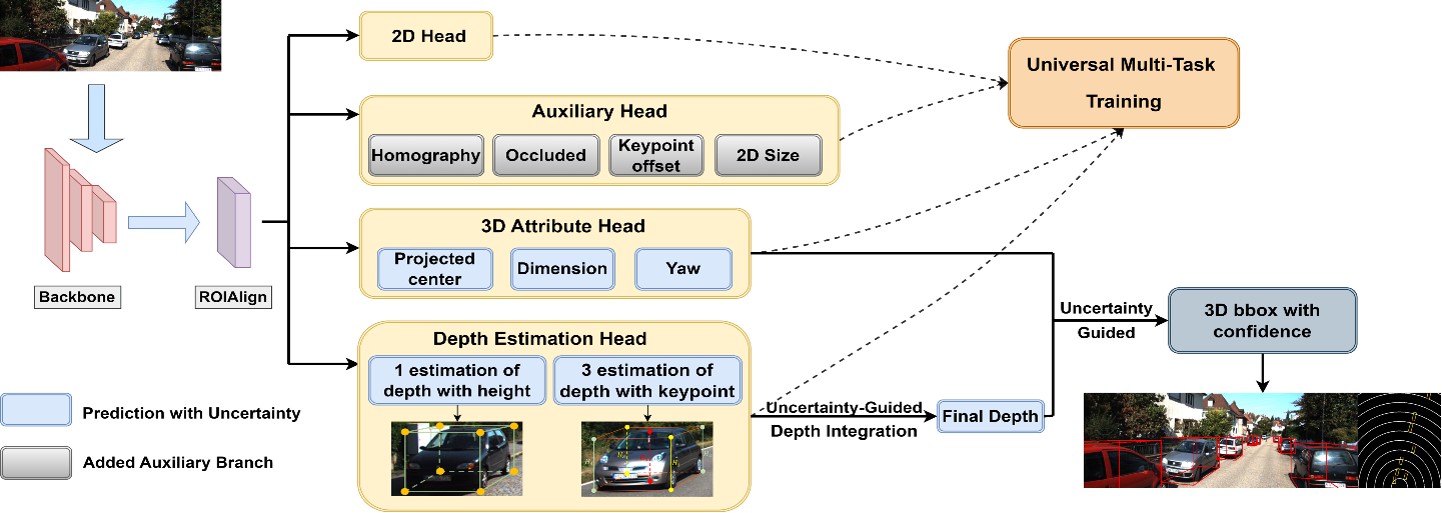
环境感知不确定性建模

MonoAux: Fully Exploiting Auxiliary Information and Uncertainty for Monocular 3D Object Detection, Cyborg and Bionic System(IF 10.5), 2024
- 不确定性不可避免,不应忽视
- 量化不确定性对自动驾驶安全至关重要
- 考虑不确定性能有效提升感知精度
- 为预测、规划提供重要参考信息

📝 代表性成果
- Zhenglin Li, Wenbo Zheng, Le Yang, Liyan Ma, Yang Zhou, Yan Peng. MonoAux: Fully Exploiting Auxiliary Information and Uncertainty for Monocular 3D Object Detection. Cyborg and Bionic Systems, 2024, 5: 0097.
- Jiasen Wang, Zhenglin Li, Ke Sun, Xianyuan Liu, Yang Zhou. DVPE: Divided View Position Embedding for Multi-View 3D Object Detection. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pp. 6877-6885. 2024.
- Zhenglin Li, Tianxin Yuan, Liyan Ma, Yang Zhou, Yan Peng. Target Detection for USVs by Radar-vision Fusion with Swag-robust Distance-aware Probabilistic Multi-modal Data Association, IEEE Sensors Journal, 2024, 5: 20177 – 20187.
- Zhenglin Li, Lyudmila S. Mihaylova, Olga Isupova, and Lucile Rossi. “Autonomous flame detection in videos with a Dirichlet process Gaussian mixture color model.” IEEE Transactions on Industrial Informatics, 2017, vol. 14, no. 3: 1146-1154.
- Xiang Liu, Zhenglin Li, Yang Zhou, Yan Peng, Jun Luo. Camera–Radar Fusion with Modality Interaction and Radar Gaussian Expansion for 3D Object Detection. Cyborg and Bionic Systems, 2024, 5: 0079.
- Zhenglin Li, Lyudmila Mihaylova, and Le Yang. “A deep learning framework for autonomous flame detection.” Neurocomputing, 2021, 448 : 205-216.
- Chuan Lin, Guangjie Han, Qiuzi Tao, Li Liu, Syed Bilal Hussain Shah, Tongwei Zhang. Underwater Equipotential Line Tracking Based on Self-Attention Embedded Multiagent Reinforcement Learning Toward AUV-Based ITS. IEEE Transactions on Intelligent Transportation Systems, 2023, 24(8): 8580–8591.
- Ke Sun, Zhenglin Li. Sparse Data Injection Attacks on Smart Grid: An Information-Theoretic Approach. IEEE Sensors Journal, 2022, 22(14): 14553–14562.
- Zhenglin Li, Mahnaz Arvaneh, Heather E. Elphick, Ruth N. Kingshott, Lyudmila S. Mihaylova. A Dirichlet Process Mixture Model for Autonomous Sleep Apnea Detection Using Oxygen Saturation Data. 2020 IEEE 23rd International Conference on Information Fusion (FUSION), 2020, pp. 1–8.
- Wenbo Zheng, Zhenglin Li, Wenbo Xie, Songyi Zhong, Tianxin Yuan, Yan Peng. SCON: Semantic Cross-Modal Data Association Offset Estimation Network for Radar-Vision Feature Fusion. 2024 IEEE International Conference on Unmanned Systems (ICUS), 2024, pp. 1516–1520.
📝 科研项目(主持与在研项目)
- 军委科技委“XXXXXX”项目子课题,XX环境理解与XX安全控制技术研究,主持,505万元
- 国家自然科学基金青年项目,面向未知多变场景的视觉自主火灾监测,30万元,负责人
- 上海市启明星培育(扬帆专项),基于无人艇的海洋温盐场重构及传感器部署智能规划,20万元,负责人
📝 联系方式
- 邮箱:zhenglin_li@shu.edu.cn
- 地址:上海市,上海大学未来技术学院/人工智能研究院